

An algorithm without a proof is not a theorem, it’s just a conjecture. In order to prove it, we have to resort to formal methods. As Boiten explains, “the formal method process entails describing what the program is supposed to do using logical and mathematical notation, then using logical and mathematical proofs to verify that the program indeed does what it should” (source). But because of time and budget constraints, it is considered extremely quixotic to attempt any kind of formal verification on a regular software development process (unless we’re talking about some safety-critical systems, such as those running on nuclear plants).
That is why software testing is a vital part of software engineering: the only practical, rapid way to verify that an algorithm works is by testing it. This has obviously at least two downsides: 1) there can’t be absolute certainty that the program will always work, which 2) brings us to the domain of probability and therefore uncertainty. As Dijkstra famously put it, “testing shows the presence, not the absence of bugs”.
Unless formal methods become an industry standard, as Dr. Thomas wants, the only alternative we have left is good old software testing. If an algorithm without proof is a conjecture, then it’s a hypothesis, which—unlike purely mathematical conjectures—in turn can be subject to empirical verification. And there’s a name for that: the scientific method.
At this point, some terms beg for clarification. An error is a human mistake that introduces a defect in the code, which in turn causes a failure, i.e. the observed incorrect result. Many testers mistakenly confuse defects and failures, and even report the latter as the former while they’re not the same thing at all. A failure is an unexpected or undesired behavior in the system, like a browser crashing or a web component displaying an incorrect result of a mathematical formula. The failure is the behavior you can see and touch. But a defect is a very different beast, it’s an imperfection in the code itself. While the failure is the what, the defect is the why, the reason why the system is not behaving as intended.
So the tester needs to make sure that 1) the failure is reproducible, to make sure it’s not something else, and has to be able to pin down the single cause that’s producing the failure, known as a defect or bug. In this sense, finding bugs means finding the independent variable that’s causing the program failure. And that’s the very essence of the scientific method.
Describing the planetary orbits is in a way science, but it’s much more scientific to explain why planets behave like that, as Newton did with this theory of universal gravitation.
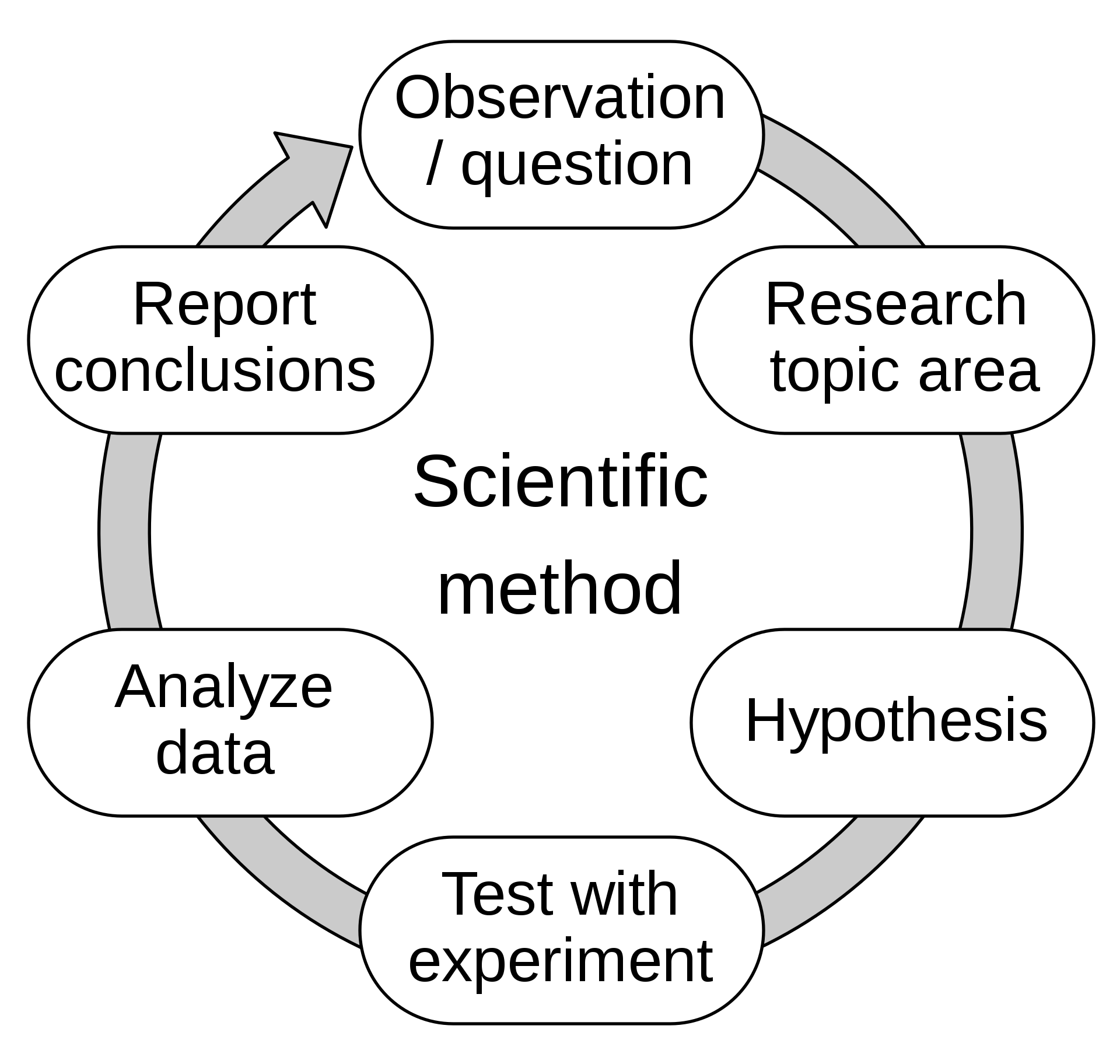
Here’s an example of how it works:
- Observation: the system fails when negative inputs are introduced.
- Hypothesis: the system fails because the algorithm is not filtering out negative inputs.
- Experiment: enter negative inputs again to see if we can reproduce the issue.
-
Analysis: did the negative inputs yield a system failure again?
-Yes: then it’s time to report the bug.
-No: then the main cause lies somewhere else, or negative inputs are simply not the single cause of the system failure. Further investigation is required. - Report: here we describe what we found and add some evidence to advance our point that the system failure was caused by this bug.
In summary, the scientific method is all about finding the causes of the observed phenomena. In software testing terms, it entails finding the bugs that are producing the failures. That is why the scientific method is literally the very foundation of what software testers do on a daily basis: if something can’t be proven correct, it has to be tested.


