
Kubernetes (k8s) is an open-source system for automating deployment, scaling, and management of containerized applications, but before you start getting to know it in detail I would like to help you to understand the need for a system like k8s. Let’s take a quick look at how software development and deployment has changed over recent years.
Splitting Monolithic apps into Microservices
As you know the applications were big Monolithic systems and all of its components were strongly coupled together, in other words, they were interconnected and interdependent. It’s likely that only one big team was in charge of those kinds of apps, managing the development, deployment and deliver as one entity. As you can imagine, changes to one part of the application require a redeployment of the whole application. Deploying and running a monolithic application usually requires a powerful server or a small number of servers that can provide enough resources to support those kinds of apps, but what happens if the number of users increases? Could we scale our monolithic app? Scaling up (vertically scale) the server could be an option, such as, adding more CPU or memory and it doesn’t need changes on the app but gets expensive relatively quickly. In the other hand, Scaling out (horizontally scale) by adding more servers and running replicas of our application probably requires big changes in our code and is not always possible. So, if any part of a monolithic application is not scalable, the whole application becomes unscalable. As you can see, the monolithic apps have some drawbacks, to name a few:
- Redeploy the entire application on each new version.
- Maintenance, in complex applications, it's not easy to make changes fast and correctly.
- Difficult to scale out.
- Reliability — If one module starts to fail it could bring down the entire application.
- Can be challenging to adopte new and advanced technologies. Since changes in languages or frameworks affect the entire application.
In order to solve the issues associated with the monolithic apps, a concept known as Microservice appeared: the idea is to break up the monolithic app into smaller, independently and deployable components. Each microservice runs as an independent process and communicates with other microservices through simple APIs.
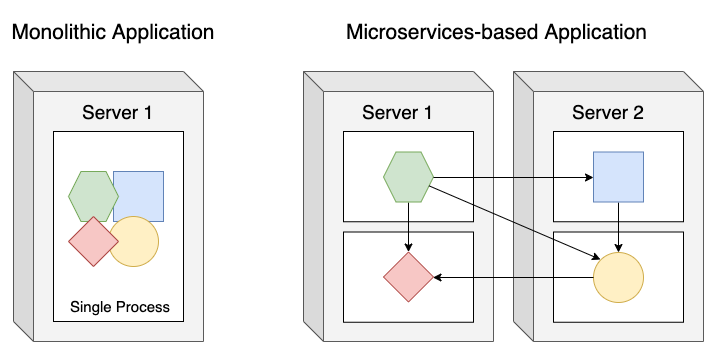
The image shows how to split monolithic apps into microservices, each new component is decoupled from each other and could be developed, deployed, updated and scaled individually. The drawbacks of monolithic apps are solved with this architecture. If you update a microservice, you are able to deploy only the updated component without redeploying the entire application. With microservices you can scale out faster and scale only the components that need updating. If you think of the reliability of your software, with this kind of architecture you avoid the possibility of the entire app failing when a particular microservice starts to fail. Your app becomes more stable. On top of this, each microservice can be written in any language, due to the fact that it is a standalone process that exposes a set of APIs for communication between them. Also, you can have one team per microservice, in this way the team could focus on a particular module of the entire system. But what happens when the number of microservices increases? The entire system becomes difficult to configure, manage and keep running smoothly. Deployment-related decisions become increasingly difficult because of not only the number of deployment combinations increase but the number of inter-dependencies between the components increases by an even greater factor. Microservices do their work together as a team, so they need to find and talk to each other. When deploying them, someone or something needs to configure all of them properly to enable them to work together as a single system. Also, since it is common to have separate teams developing each component, nothing impedes each team from using different libraries. The divergence of dependencies and the possibility of each component requirng different versions of the same libraries are inevitable. Deploying applications that need different versions of shared libraries, and that need other environment specifics, can quickly become a nightmare for the ops team. So, how can we isolate the environment of each microservice? Let’s introduce the concept of Containers.
Isolating applications using containers
When we have different microservices running on the same server we will probably need different versions of the same dependencies or have different environment requirements in general. If we have a smaller number of components, it is completely reasonable to use one Virtual Machine per component. But what happens when the number of microservices starts to grow? You should not use a Virtual Machine for each microservice if you don’t want to waste your hardware resources and spend unnecessary money, besides you are going to waste human resources to configure properly and keep up all the VMs working as expected. Instead of VMs to isolate environments, developers started using Linux Containers technologies (LXC). We allow running multiple applications on the same host machine, exposing different environments for each microservices and isolating them from each other. Behind the scenes, LXC takes advantages of two functions of the Linux Kernel, the first is Linux Namespaces in order to make sure each process sees its own personal view of the system (files, processes, network interfaces, hostname, and so on). The second one is Linux Control Groups, know as cgroups, which limits the number of resources the process can consume (CPU, memory, network bandwidth, and so on). While container technologies have been around for a long time, they’ve become more widely known with the rise of the Docker container platform. Docker was the first system that made containers easily portable across different machines. Simplifying the building and packaging of our apps and its dependencies, into a portable package that can be used to distribute the application to any other machine running Docker. It offers a high-level tool with several powerful functionalities:
- Component re-use. Any container can be used as a “parent image” to create more specialized components.
- Automatic build. Docker includes a tool for developers to automatically assemble a container from their source code, with full control over application dependencies, build tools, packaging, etc.
- Versioning. Docker includes git-like capabilities for tracking successive versions of a container, inspecting the diff between versions, committing new versions, rolling back, etc.
- Tool ecosystem. Docker defines an API for automating and customizing the creation and deployment of containers.
- Portable deployment across machines. Docker containers can be transferred to any Docker-enabled machine.
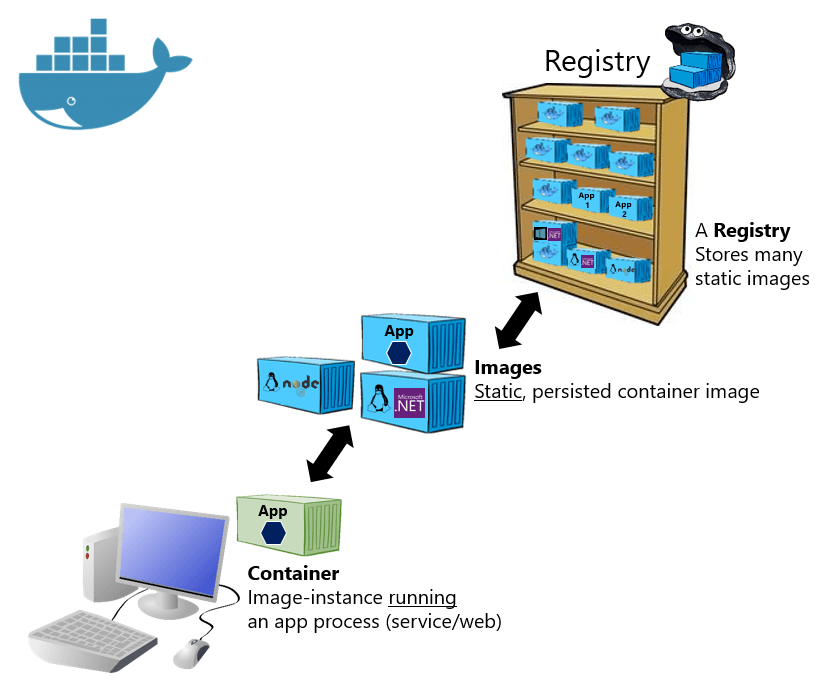
There are three main concepts about Docker that you should know before we’ll start learning Kubernetes. First, Images: a Docker-based container image is something you package your application and its environment into. The Registry, Docker defines a hub or repository to store all the images that the users publishes and makee it easier to share these images between the developers. Lastly, we already talked about it, Containers, a regular Linux container created from a Docker-based container image.
Introducing Kubernetes
As we mentioned in the earlier sections, the applications can grow and become a huge set of microservices with different environment requirements each one. To solve this problem, we should move all our microservices to containers using platforms like Docker. At this point, we are going to have a set of containers, so now, the definition makes more sense, Kubernetes is an open-source system for automating deployment, scaling, and management of containerized applications. It relies on the features of containers to run applications without having to know any internal details of these applications and without having to manually deploy these applications on each host. Because these apps run in containers, they don’t affect other apps running on the same server.

Some of the benefits of using Kubernetes are listed below.
- Simplifying Applications deployments: deploying applications through k8s is always the same, whether your cluster has only a couple of nodes or thousands of them. The size of the cluster makes no difference at all. Additional cluster nodes simply represent an additional amount of resources available to deployed apps. Kubernetes exposes a single deployment platform, developers can start deploying applications on their own and don’t need to know anything about the servers that make up the cluster
- Achieving better use of hardware: telling k8s to run your app, you’re letting it choose the most appropriate node to run your application on based on the description of the application’s resource requirements and the available resources on each node.
- Service discovery and load balancing: No need to change your application to use an unfamiliar service discovery mechanism. Kubernetes gives containers their own IP addresses and a single DNS name for a set of containers and can load-balance across them.
- Health checking & Self-healing: Kubernetes monitors your app components, restarting containers that fail, replaces and reschedules containers when nodes die, kills containers that don’t respond to your user-defined health check, and doesn’t advertise them to clients until they are ready to serve. This frees the ops team from having to migrate app components manually.
- Horizontal scaling: While the application is running, you can decide you want to increase or decrease the amount of copies, and Kubernetes will spin up additional ones or stop the excess ones, respectively. You can even leave the job of deciding the optimal number of copies to Kubernetes. It can automatically keep adjusting the number, based on real-time metrics, such as CPU load, memory consumption, queries per second, or any other metric your app exposes.
I hope that this brief explanation was helpful for you to understand why as a developer we need amazing platforms like Kubernetes.


