

This document outlines the product requirements for developing a Retrieval-Augmented Generation (RAG) AI solution that utilizes proprietary internal information or a specific website to provide contextually aware responses and content generation. The hypothesis is that conversations created from a bot based on RAG will be highly contextual with minimal hallucination.
If you want to learn how it compares to a fine-tuning approach, learn more with the second part of this guide.
Index
-
Project definition
1.1 Purpose and Scope
1.2 Background and Objectives
1.3 Product Description
1.3.1 Data sources 1.3.2 Key Features -
Solution
2.1 Scope phasing
2.2 Procedure
2.3 Architecture Diagram
2.4 Data Sources Integration
2.4.1 Basic text files
2.4.2 Structured data
2.4.3 Web Scraping
2.5 Multiple Data Sources Integration
2.5.1 Challenges in the integration
2.5.2 Solutions - Results
- Conclusions
- Recommendation
1. Project definition
1.1 Purpose and Scope
This document outlines the product requirements for the development of a Retrieval-Augmented Generation (RAG) AI solution designed to integrate and utilize data from proprietary internal information or a specific website (let’s call it custom information) to limit the scope of data and information. The solution will enable the AI to retrieve the ‘custom information’ and use it to inform generative AI interfaces, providing enhanced, contextually aware responses and content generation.
Hypothesis: The conversations created from a bot based on RAG will be highly contextual with minimal hallucination.
1.2 Background and Objectives
- Problem Statement: Businesses need to provide personalized and relevant interactions and content to their users. Current AI interfaces lack the capability to dynamically pull in custom data sources during the generation process, resulting in generic responses and hallucinations, which can misguide the user.
- Objective: To build a RAG AI solution that can seamlessly retrieve data from a custom information repository (internal or public) and use that data to generate informed and contextualized content for customer interactions.
1.3 Product Description
A RAG AI platform that integrates with ‘custom information’ to fetch real-time data for use in generative AI applications such as customer service chatbots, personalized content creation, and data-driven decision support systems. RAG relies on specific content and the prompts can be engineered to reduce and even eliminate hallucination.
1.3.1 Data sources
For the phase I, focus on following data sources
- Web content (either public or internal). Okay to start with public content
- Text files
- PDF files
1.3.2 Key Features
- Data Integration:
- Ability to ingest data from custom data sources (files or HTML)
- Ability to connect with various customer website architectures to retrieve data.
- Ability to connect to specific data sources like support tickets or internal knowledge-based like confluence.
- Store the data in a data store that supports indexing unstructured content (e.g. vector DB)
- Query the unstructured data to find relevant responses
- Contextual Understanding: Leverage retrieved data to enhance the AI’s understanding of context for better content generation.
- User Interface: A user-friendly interface for customers to define parameters and preferences for data retrieval.
- Compliance and Privacy: Ensure that all data retrieval and processing comply with relevant data protection regulations.
2. Solution
Addressing the challenge of enhancing AI interactions for businesses, our solution introduces a RAG AI system. This system overcomes the limitations of current AI interfaces by dynamically integrating custom data sources, both internal and public, into the response generation process. This document outlines our approach, covering the scope, phased implementation, procedural steps, and the architectural design. It also details the integration of multiple data sources, ensuring AI responses are both informed and contextually relevant, thereby transforming customer engagement with personalized experiences.
2.1 Scope phasing
This work will be executed in phases. In each phase, responses will be compared for custom content vs plain AI scenarios to better fine-tune the output. Custom information, if available, will be fed to the AI for each query to construct a concise response from the AI using the content.
- Upload basic text files
- Upload structured data
- Web scrape content
- Upload pdf, doc, docx files
- Support for tables and charts in documents
- Bulk upload documents using s3
- Onboarding with api
2.2 Procedure
In the development of a RAG system, various strategies are employed as solutions to specific challenges encountered during different phases of the system’s development. These strategies enhance the system’s efficiency, accuracy, and overall performance. Here is a step-by-step procedure followed to create the RAG system, highlighting the strategies used across the steps to fulfill the objectives of the project:
-
Information Collection: This phase involves gathering relevant documents and data for the RAG’s intended domain.
a. Cleaning Strategy: Applied here to strip unnecessary elements and format the remaining content, aiding in efficient concept extraction. - Analysis of Query Types: Identifying and understanding the types of queries the RAG system needs to address. The project requires addressing key aspects of the ‘Payes’ data using the ‘Pokedex’ CSV file. This file includes essential details like addresses, names, and conditions related to Payes. Additionally, the project will tackle general financial questions.
- Database Creation: Pinecone is used for storing vectors, and Postgres manages the loaded sources and allowed topics.
-
Chunking Strategy and Embeddings: Involves defining document segmentation and creating efficient data representations.
a. Chunking Strategy: Considered during this phase to optimize data storage and management.
b. Embeddings: Utilizing the text-embedding-ada-002 model to create dense embeddings that accurately reflect semantic content. This feature is crucial for enhancing the retrieval process in our system, ensuring that the information fetched is both semantically relevant and contextually appropriate. The model’s efficiency with various text lengths allows us to handle extensive databases effectively, an essential aspect for our project’s scale. Additionally, the cost-effectiveness of text-embedding-ada-002 makes it a practical choice, enabling us to maintain high-quality output without incurring high expenses -
Document Retrieval Logic Implementation: Developing a system to retrieve documents from the database.
a. Self Query Retriever Strategy: Crucial in translating natural language queries into structured queries that the database can understand and respond to. This approach is useful because it allows for more intuitive and flexible querying of complex data sets, solving the problem of interfacing between natural language requests and structured database queries. This approach involves storing documents with relevant metadata, which is then used to generate conditions during the querying process. -
Integration with the LLM (OpenAI): Connecting the RAG system with OpenAI’s language model.
a. Pre-trained Prompt: Employed to tailor responses ensuring comprehensive and relevant details are included from the retrieved files. This feature is used for all queries, whether they require content from the Pokedex file or not. Although the pre-trained prompt is tailored for Pokedex-related topics, the AI adapts when handling other subjects. It maintains the structure of the answers provided in the examples, ensuring consistency in every response. - Customized Decision-Making Logic: Implementing logic to determine when to use the documents versus the LLM’s general knowledge.
2.3 Architecture Diagram
Our focus is on two key actions: storing and querying documents. It’s important to note that the querying flow is uniform across all document types; this means that regardless of whether the source is a DOC, TXT, CSV, or a website, the steps and strategies we use for querying remain the same. In contrast, while the steps for storing documents are consistent, the strategies we apply can differ based on the specific type of document. We will delve into these strategy variations later. Accompanying this section, you’ll find diagrams that outline the workflow for managing the document sources
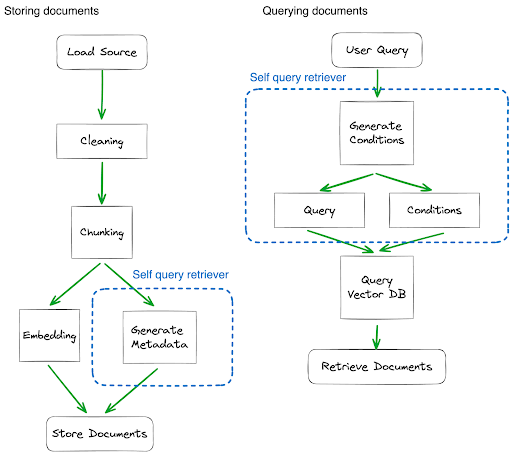
2.4 Data Sources Integration
2.4.1 Basic text files
- Overview
| Engine | GPT-4 Turbo |
|---|---|
| Cleaning Strategy | formatting the text using markdown |
| Chunking Strategy | based on token limit |
| Embedding | text-embedding-ada-002 |
| Vector DB | Pinecone |
| Content Source | text files |
| Custom prompt | Yes |
- Observations
- OpenAI’s technology is utilized to generate structured text in markdown format, tailored to the specific context of the content.
- Since the text files are small, no chunking strategy was necessary.
- With the chosen GPT version and embedding along with a standard index on vector db, the results were very good.
2.4.2 Structured data
- Overview
| Engine | GPT-4 Turbo |
|---|---|
| Cleaning Strategy | formatting the text using markdown |
| Chunking Strategy | No |
| Embedding | text-embedding-ada-002 |
| Vector DB | Pinecone |
| Content Source | csv files |
| Custom prompt | Yes |
- Observations
- We use Markdown to format the data into a list with the structure ‘Title: Content’, allowing the AI to efficiently infer the main concepts.
- Chunking is unnecessary for structured data, as it can disrupt the data’s integrity.
- We apply a self-query retrieval strategy across all sources. But this approach is particularly effective in structured data, enabling precise identification of data that matches user-specific queries.
- To effectively manage the CSV structure, we’ve implemented metadata creation for document retrieval from VectorDB. This process filters out only the relevant CSV rows. Our project, using the Pokedex file, has designed metadata specifically based on this file’s structure. We’re addressing two main queries: a. Retrieving a payee using their name and, optionally, a city. b. Retrieving a payee using a PO Box address and, optionally, a city. To achieve this, we’ve incorporated PO Box numbers and city details into our metadata. This allows for precise data retrieval and filtering, ensuring users find the exact payees they need.
- We’ve introduced a pre-trained prompt feature specifically for the Pokedex file, enhancing AI responses. It uses examples to tailor answers, ensuring comprehensive and relevant details from the Pokedex are included in every response.
2.4.3 Web Scraping
-
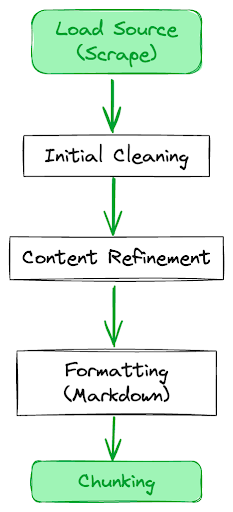
Architecture Diagram: The following diagram expands on the data cleaning step for website sources, as initially introduced in the ‘Architecture Diagram’ section. It delineates the process for refining scraped web data:
- Initial Cleaning: Strip out unnecessary HTML tags (e.g., meta, img, head, footer, script, style) and remove attributes (like class, id, style) from the remaining tags.
- Content Refinement: Submit the cleaned content to OpenAI. This step involves filtering out non-essential elements such as menus or social media prompts, retaining only pertinent information.
- Formatting for Clarity: The final step uses OpenAI to reformat the content in markdown. This creates a clear hierarchy, enhancing the AI’s response quality for future interactions.
- Overview
| Engine | GPT-4 Turbo |
|---|---|
| Cleaning Strategy | Removing unnecessary content and format it using Markdown |
| Embedding | text-embedding-ada-002 |
| Chunking Strategy | based on token limit |
| Vector DB | Pinecone |
| Content Source | websites |
| Custom prompt | Yes |
- Observations
- Went with a size-based chunking strategy for easy demonstration purposes.
- The tool successfully scraped websites that permit scraping, but it failed on websites like www.nerdwallet.com which have bot blockers to prevent scraping.
2.5 Multiple Data Sources Integration
2.5.1 Challenges in the integration
To effectively integrate multiple data sources, we must overcome several challenges:
- Ensure data relevance: We need to match the retrieved data accurately with user queries, considering that our documents cover various topics.
- Adapt to source-specific methods: Different approaches are required for handling structured data (like CSV files, where we need to select the correct lines) and unstructured data (like web scrapings, where we need to identify the most relevant information).
2.5.2 Solutions
To address these challenges, we’ve implemented two key solutions:
- Topic Area Metadata: During the storage process, each document is tagged with a ‘topic_area’ metadata. This metadata is then used in the query process to generate a list of topic areas relevant to the user query. This approach allows us to not only select the pertinent documents from the vector database but also filter them by the correct topic area.
- Quality Metadata: We’ve introduced another metadata called ‘quality’, which assesses whether a document’s chunk is contextually coherent with the entire document and if it contains self-explanatory ideas that begin and end within the chunk. By filtering for high-quality chunks during the query process, we aim to retrieve only the most relevant and coherent documents.
3. Results
To obtain the results, we prepared the RAG model by uploading the Pokedex CSV file and incorporating content scraped from a webpage. For the purpose of comparison, we used the “gpt-4-1106-preview” version of OpenAI’s model as both the RAG and the base model. This allowed us to compare the answers obtained from each model in response to the same set of questions, ensuring consistency in the technological framework for an accurate assessment.
Following this explanation, a table is presented to compare the responses from the base model and the RAG model. Additionally, the table includes the time each model took to generate the answers. It’s important to note that these times are subjective, as they depend on factors such as internet connection, the state of OpenAI’s servers, and the size of the answers generated. However, the main intention is to observe the tendency of each model in terms of the duration required to produce the answers. This comparative analysis aims to provide insights into the efficiency and responsiveness of each model under varying conditions.
| Base model | RAG |
|---|---|
| I need to send a payment to Huntington National Bank in Ohio | |
To send a payment to Huntington National Bank:
|
For sending a payment to Huntington National Bank in Ohio, use the following address:
|
| Time 18s | Time 30s |
| All Chase payees in Arizona | |
|
Here is the address for Chase in Arizona:
|
| Time 10s | Time 32s |
| give me the 5 Budgeting Misconceptions You Should Stop Believing | |
|
It seems you're looking for advice on budgeting misconceptions. Here are five common misconceptions you should be aware of:
|
| Time 13s | Time 39s |
| some misconceptions about budgeting | |
|
Here are some common misconceptions about budgeting that may hinder financial progress:
|
| Time 27s | Time 28s |
| What is budgeting? | |
Budgeting refers to:
|
Budgeting is the process of creating a plan to manage your money, which allows you to:
|
| Time 9s | Time 32s |
| good reasons to implement a budget | |
|
Good reasons to implement a budget include:
|
| Time 17s | Time 43s |
| How do I budget? | |
To start budgeting effectively:
|
To create a budget, follow these steps:
|
| Time 13s | Time 31s |
4. Conclusions
- Effective Data Retrieval from Structured Sources: The RAG system demonstrated proficiency in integrating with structured data, specifically with the Pokedex CSV file, aligning with the project’s objective to retrieve data from a custom repository for informed content generation.
- Integration Issues with Unstructured Data: The system encountered challenges in integrating unstructured data sources, which impacted its ability to seamlessly retrieve data and generate contextualized content, partially fulfilling the project’s objective.
- Comparative Performance with Base Model: When incorporating unstructured data, the RAG’s performance was observed to be similar to that of the base model, suggesting a need for further improvement to meet the objective of generating more contextualized and informed content. Notably, this similarity in performance becomes more apparent with general questions, where the RAG and base model yield comparable results. However, in scenarios involving specific inquiries, such as those related to the Pokedex or detailed questions about web page content, the RAG demonstrates enhanced performance. Despite this, as the questions become more general, the tendency of the RAG’s responses increasingly aligns with those of the base model.
- Complexity in Development Process: The process of customizing responses based on the structure of retrieved documents was found to be complex, potentially affecting the efficiency of customer interactions and the overall objective of the project.
- Time Efficiency in Response Generation: the base model generated responses faster than the RAG model. The RAG’s slower performance is due to its complex process of retrieving information from the vectorDB, which lengthens response time. This highlights a trade-off between detailed data integration and time efficiency in AI models.
5. Recommendation
Based on these conclusions, it’s recommended to undertake an extensive assessment of the complexities that may arise from integrating structured and unstructured data within the RAG system. This assessment should weigh the trade-offs between complexity and benefits when implementing advanced strategies such as semantic re-ranking, the Diversity Ranker, or the LostInTheMiddleRanker. Specifically, semantic re-ranking employs a two-phase approach, initially, it quickly retrieves documents, which is then followed by a more detailed and slower re-evaluation by a reranker for enhanced accuracy. In contrast, the Diversity Ranker aims to increase the variety of content in RAG systems by selecting varied documents. Meanwhile, the LostInTheMiddleRanker is designed to optimize the arrangement of documents in the context window. It strategically places the most pertinent documents at the beginning and end, effectively addressing the tendency of language models to neglect content in the middle.
If the evaluation suggests that the complexities outweigh the benefits, the development of a Mixture of Experts (MoE) structure should be considered. This structure involves fine-tuning specialized models for specific data types and integrating an orchestrator model to select the appropriate expert (including the RAG system) for responding to user queries. This approach aims to optimize the handling of both structured and unstructured data, enhancing the system’s overall efficacy in producing accurate, contextually relevant content for customer interactions while carefully managing the increase in project complexity.


