

In our exploration of artificial intelligence, certain models distinctly stand out, and GPT among them, exemplifies both the peaks and pitfalls of AI. As these models grow more complex, the challenges we face also multiply, especially concerning biases related to the training data. This is further complicated by Reinforcement Learning from Human Feedback (RLHF), where the model is refined based on human input. We’ll delve into how different factors like temperature settings and linguistic differences can shape GPT’s inherent biases.
GPT’s Numeric Preferences:
To start, we picked the gpt-3.5-turbo model and gave it a simple task, just to highlight GPT’s decision-making patterns. Though this doesn’t capture all potential biases, it offers a glimpse into its tendencies with respect to numbers. We prompted the model 1000 times with the following instruction:
“Choose an integer number between 1 and 100”
Then, we parsed the numbers from the answers with a set of heuristic rules.
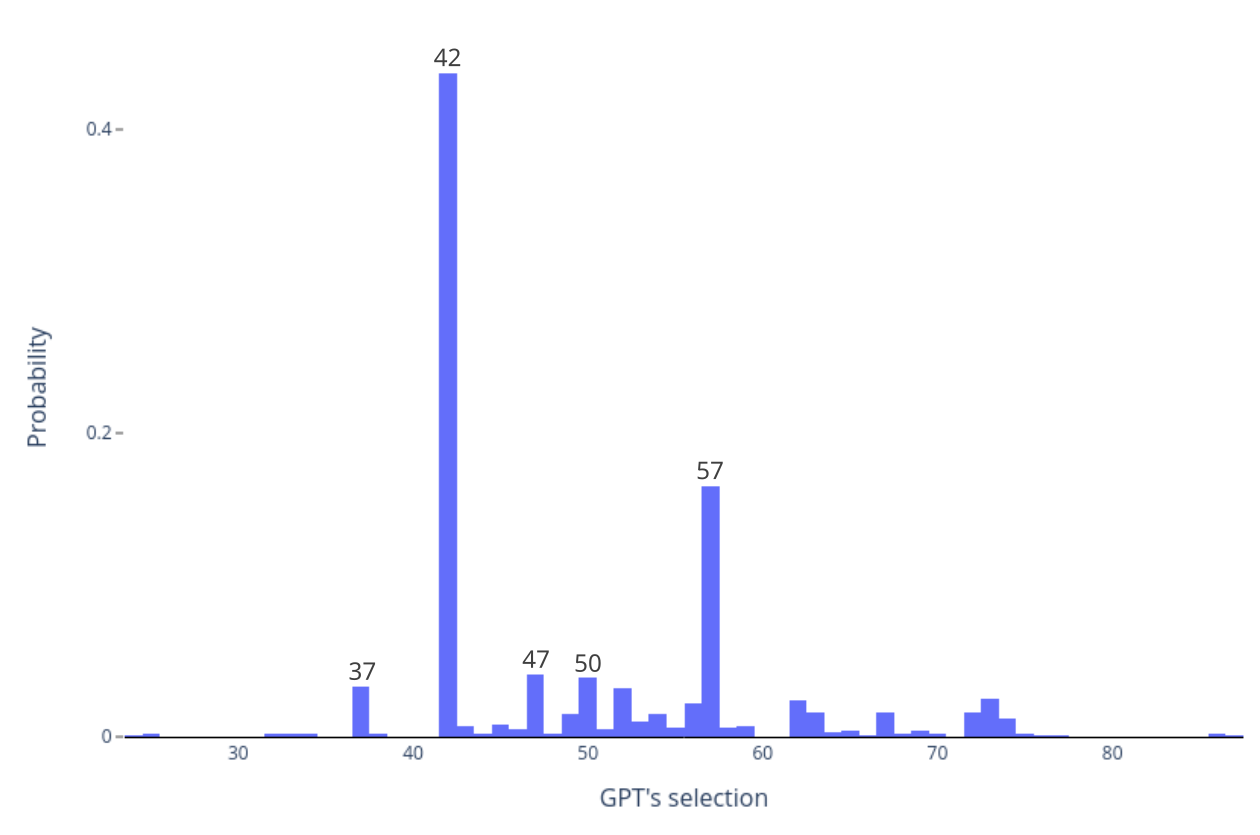
Numbers seem straightforward, but within GPT, they take on added significance. The number 42, for instance, isn’t just another integer. Thanks to “The Hitchhiker’s Guide to the Galaxy” by Douglas Adams, where 42 is deemed the “answer to life, the universe, and everything,” GPT displays a bias towards it.
Following 42, numbers containing the digit ‘7’ also emerge as favorites, specifically 57, which is the second most selected. The significance of 7, from the seven wonders to the seven days of the week, permeates multiple cultures across history. Given GPT’s diverse training data, its affinity for this number isn’t surprising.
We also wanted to understand how GPT would respond if given a list of numbers in a random order rather than a sequential one. Would its preference for 42 and 7 remain consistent or reveal new tendencies? To solve this, we repeated the previous experiment with the following instruction:
“Choose a number from the following list: [4, 75, 94, 16, 60, …]”
Where the list contains all integers between 1 and 100, and is randomized for each trial (it is shown truncated to avoid clutter).
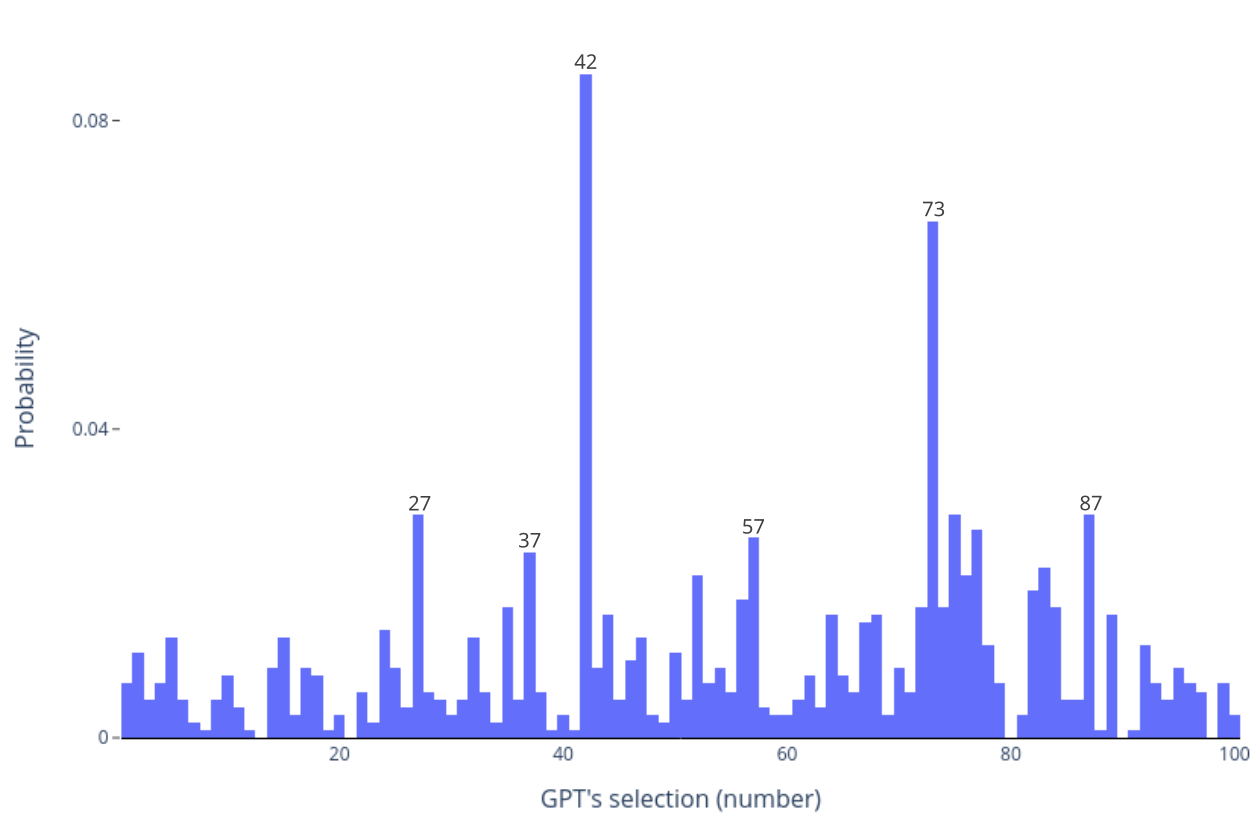
From the data with randomized number sequences, 42 remains a favorite, though its lead narrows -as seen looking at the probabilities. This leads us to the question: How does the position of numbers in the list impact GPT’s selections?
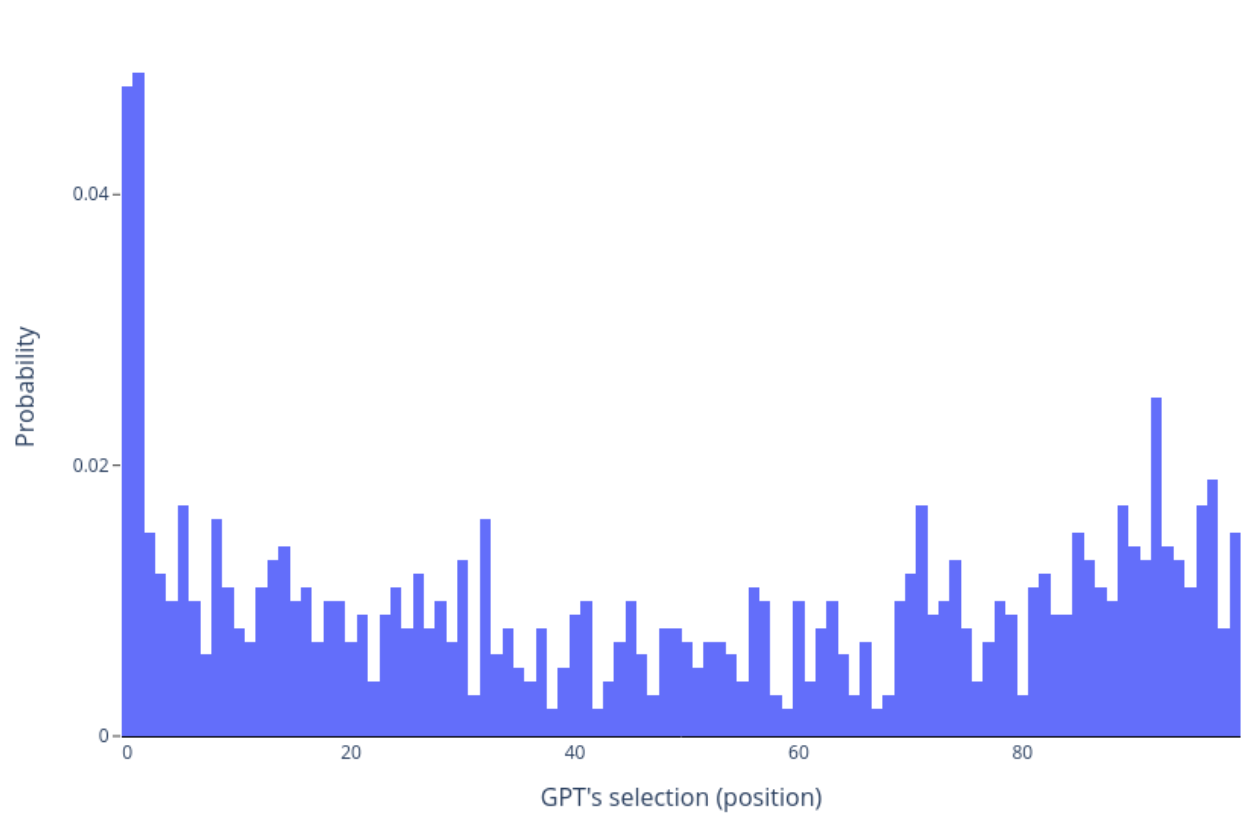
Our findings show that GPT doesn’t just have number preferences; it also exhibits a bias regarding the position of the number. Notably, in random lists, GPT tends to select the first numbers, showing an underlying pattern in its decision-making.
A critical note: our observations so far are based on GPT’s default settings. However, there is more to its decision making than just its neural structure; it’s also about its adjustable parameters. Exploring all of these would be exhaustive. For this discussion, we’ll focus on a key parameter: temperature. Simply put, temperature adjusts GPT’s response predictability. A low setting yields more consistent answers, while a higher setting introduces randomness. Let’s now examine how varying the temperature affects GPT’s biases.
Exploring Temperature’s Impact on GPT’s Choices
The role of temperature in GPT’s decisions is crucial. Essentially, temperature adjusts how random or biased GPT’s answers are. Using this concept, we conducted a series of tests across the entire temperature range provided by the API.
Our tests used the gpt-3.5-turbo model with all default settings except for the varied temperature. Each temperature value, ranging from 0 to 2 in 0.1 increments, was tested 200 times.
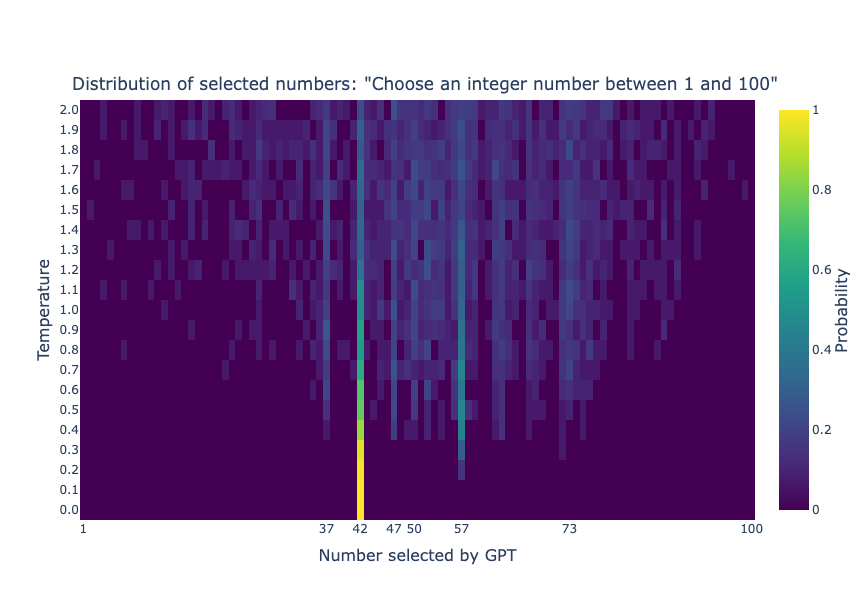
The above heatmap reveals clear patterns. At lower temperatures, GPT strongly prefers certain choices, like the number 42. But as the temperature rises, GPT’s choices diversify. Lower temperatures lead to more predictable or “biased” choices, while higher temperatures produce a wider variety of responses.
This highlights the significant role of temperature in GPT’s decision-making, emphasizing the need to adjust such parameters for desired results.
Quantifying bias with entropy
To effectively assess bias, we need clear metrics. Enter entropy: a concept both misunderstood and utilized to similar extents. Specifically, we will employ normalized entropy, which confines values within the (0,1) range. Bear with me as we delve a bit into its mathematical definition:
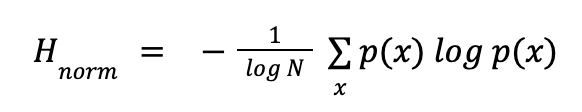
Where:
- N represents the number of unique values in the results
- p(x) is the probability of occurrence of the value x
In this context, it suffices to know that we can use entropy to measure the randomness of a system. Within our tests, it quantifies the degree of variability in GPT’s answers.
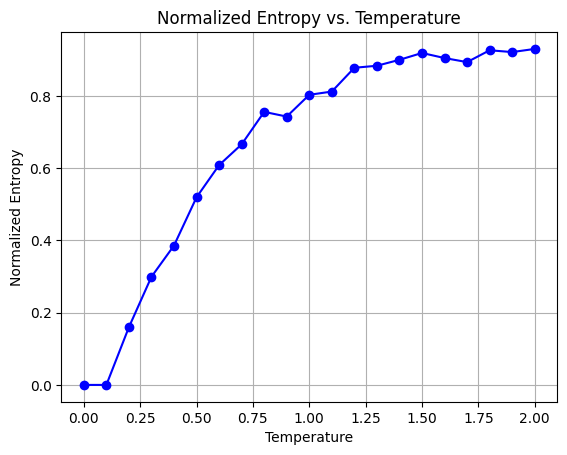
In our analysis, entropy gauges the “randomness” of GPT’s decisions. When all choices align with a single number, entropy is zero. Conversely, entropy reaches a normalized value of 1 when choices are fully random. . Thus, GPT’s “bias” can be viewed as 1 minus its entropy.
From the data, it’s clear that at T = 0, bias is highest, with exclusively the number 42 being chosen. As temperature rises, this bias diminishes, indicating increased randomness. Notably, bias levels out around T = 1.5, meaning consistent randomness is achieved across various temperatures thereafter.
Conclusively, temperature is a key factor in GPT’s decision-making, and it’s essential to understand how changing temperature influences results.
Impact of Language: Comparing English and Chinese
Language can significantly influence an LLM’s behavior. Given GPT’s multilingual capabilities, we explored how its biases might change when prompted in Chinese versus English. The prompt chosen in this case is a direct translation of the one we used in English:
“选择 1 到 100 之间的整数”
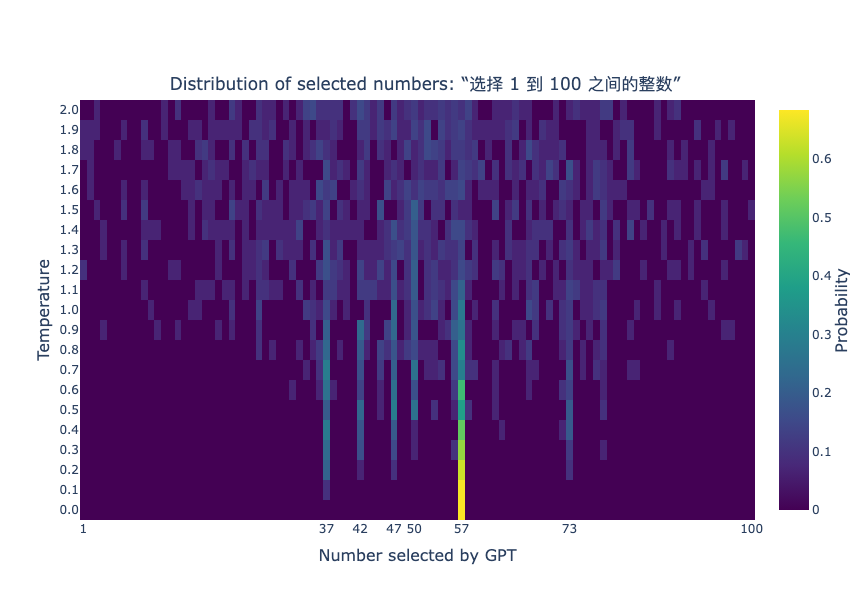
The heatmap reveals a notable change: 42 is no longer the top pick. At temperature T = 0, the model consistently selects 57, the second to most picked in the English version. Given that 57 doesn’t hold any special significance in Chinese culture, we attribute its prominence to the absence of 42. This shift suggests cultural or linguistic differences could impact number preferences in a similar way that it affects other domains (for an example on this, try asking ChatGPT for a list of foods both in English and in Chinese)
It’s straightforward to think 42’s absence is due to its reduced cultural importance in Chinese contexts, and that might be the case. It is also interesting to explore a broader range of languages to assess how differences in training data can impact bias. However, we must also note that slight phrasing alterations, even in the same language, can affect GPT’s choices. While language clearly influences GPT’s outputs, this also underscores the model’s susceptibility and the need for careful wording, especially across different languages.
Concluding thoughts
We dived into a handful of factors that might skew our responses towards certain options over others, and this has brought forth several key insights. LLMs are an impressive feat in AI, but they have their inherent tendencies, and it’s better to acknowledge them if we want to get predictable results.
Temperature plays a critical role, not just as a minor detail but as a primary influencer of GPT’s bias. Adjusting the temperature can make the model’s decisions range from highly predictable to varied, emphasizing the significance of its correct setting for optimal results.
Additionally, language is pivotal. The model’s responses can differ drastically between English and Chinese. This shows the deep connection between data, cultural context, and the underlying algorithm.
These observations are not just of academic interest. They have practical implications for everyone interacting with AI, from developers to end-users. For diverse applications, from content creation to decision-making, it’s vital to recognize and understand these biases. As we proceed, the challenge lies in leveraging LLM’s capabilities while being aware of their nuances, aiming for AI that meets our goals and aligns with our values.


