

We’ve got an exciting topic to dive into today: the impact of different prompts on the performance of Large Language Models (LLM). When it comes to interacting with models like ChatGPT, we all know the importance of using the right prompts to get coherent and detailed responses. One prompt that has gained recognition for its effectiveness is “Let’s think step by step”. It helps structure the model’s thinking process and generate more organized and insightful answers.
The quest for better results
But here’s the thing: we wanted to see if we could take it up a notch. So, we started exploring prompts that could potentially improve upon the already powerful “Let’s think step by step” prompt. To accomplish this, we leveraged the OpenAI Evals framework—a standardized methodology for evaluating language model responses—and compared the results of various prompts. After an extensive analysis where we compared more than 100 alternative prompts, there was one prompt that stood out and deserved a deeper analysis: “Show step by step the way to arrive to the right solution.” This prompt takes the concept of step-by-step thinking to the next level, providing even more detailed guidance to ChatGPT and similar models. The goal was to help these models generate accurate answers by nurturing a deeper understanding of the problem at hand.
Methodology and Analysis
To ensure a comprehensive analysis, we designed a series of tests covering diverse knowledge domains, such as chemical equation balancing and Euclidean geometry. We repeated certain topics to gather a substantial amount of data. Each test involved adding either the “Let’s think step by step” prompt or the “Show step by step the way to arrive to the right answer” prompt to the system content. We kept all other factors constant to maintain consistency. This is an example of a single test.
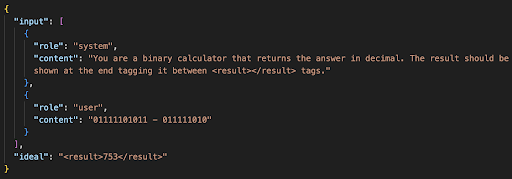
To check each test and find out if its result was correct or not, what we did was the following: the test was satisfactorily solved in the case in which our “ideal” was found in the response generated by the model, which contains the correct answer for the test in a specified format, such as enclosed within
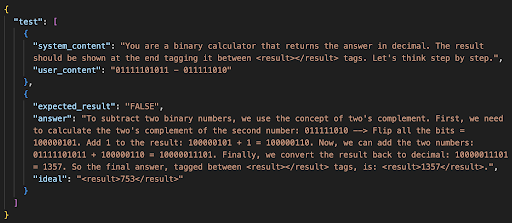
To see it better this is an example of the test with “Let’s think step by step” concatenated in the system content, its answer and if the test was solved correctly or not.
Findings: A Clear Winner Emerges
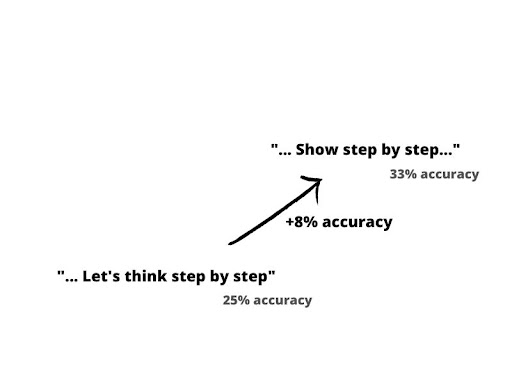
When we crunched the numbers, a clear pattern emerged. Across more than 500 evaluations and 25 repetitions, the prompt “Show step by step the way to arrive to the correct answer” consistently outperformed “Let’s think step by step” in terms of generating correct responses. The average accuracy for the former was 32.05%, while the latter scored 24.46%, with a relative standard error of 0.57%.
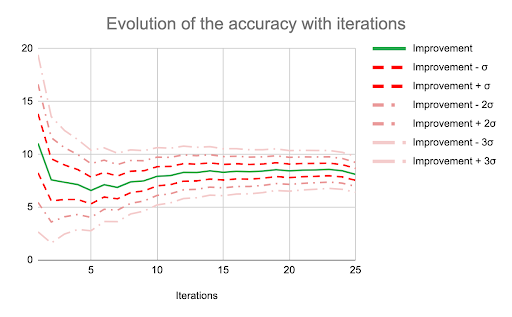
The graph below shows the trend of convergence for the the difference between the performances of the prompts, that is, the improvement of the prompt “Show step by step the way to arrive to the right answer” with its standard deviation and gives and idea of the number of iterations needed for a robust measurement of the error.
Conclusion: It’s All About Optimization
In conclusion, our findings demonstrate that the “Show step by step the way to arrive to the correct answer” prompt yields better results than “Let’s think step by step” for the tasks evaluated. However, it’s important to remember that the models’ output is essentially unpredictable and there’s always a chance that the prompts considered in this article are not the best suited for any kind of problem. To mitigate this impact, we recommend executing evaluations multiple times (like our 25 repetitions) and most importantly, noting that at the end of the day this is a trial and error process that requires hands-on experimentation to reach the prompt that most effectively addresses your problem.
As developers we are constantly looking for optimization. Carefully picking the right prompt can save us a lot of work and it can create more reliable ways to work with LLMs. Let’s keep experimenting and looking for ways to take advantage of these tools.


